 分布式链路跟踪之ELK日志
分布式链路跟踪之ELK日志
你好呀,我的老朋友!我是老寇,欢迎来到老寇云平台!
话不多说,讲一讲分布式链路跟踪之ELK日志!
# 服务治理
在微服务治理中,最重要的莫过于日志、链路和指标,为什么?因为微服务调用链路错综复杂,服务节点的数量成千上万,所以,基础设施建设重中之重,否则,出现问题,排查将是一大难题。
# 技术栈
# log4j2
像log4j、logback、log4j2都是Java日志记录框架,而slf4j是日志门面,统一日志API,隐藏具体的日志实现。
log4j2是log4j的升级版,性能卓越,支持异步日志,也是目前性能最好的Java日志记录框架。
log4j2不会给Java垃圾回收器带来任何负担,这是通过基于 LMAX Disruptor (opens new window)
技术和JVM零GC实现
# kafka
什么是事件流处理?
事件流处理是 从事件源实时捕获数据的做法
例如,从数据库,传感器,移动设备实时捕获数据,持久化存储这些这些事件流以供检索、操作和处理。
kafka就是一个事件流处理平台
- 发布(写入)和订阅(读取)事件流,包括连续导入/导出来自其他系统的数据
- 根据需要持久可靠地存储事件流
- 在事件发生时(实时)或回顾性地处理事件流
kafka如何工作?
kafka
是一个分布式系统,由服务器和客户端组成,这些服务器和客户端通过高性能 TCP网络协议 (opens new window)
通信。
# micrometer
micrometer官方地址 (opens new window)
micrometer【千分尺】为最流行的可观测性系统在检测客户端提供了一个简单的外观,允许您检测基于JVM的应用程序代码,而不受供应商限制。
注意:Spring Cloud Sleuth 迁移至 Micrometer Tracing
micrometer是最流行的可观测性工具的应用程序可观测性外观
tracing是提供对跟踪器和跟踪系统报告器的跟踪抽象
注意:tracing官方提供对Brave和OpenTelemetry的桥接,tracing只是一个跟踪抽象,类似slf4j门面,具体的链路跟踪由Brave或OpenTelemetry来实现。
<dependencys>
<dependency>
<groupId>io.micrometer</groupId>
<!-- 集成Brave -->
<artifactId>micrometer-tracing-bridge-brave</artifactId>
<version>1.3.3</version>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<!-- 集成OpenTelemetry -->
<artifactId>micrometer-tracing-bridge-otel</artifactId>
<version>1.3.3</version>
</dependency>
</dependencys>
Brave和OpenTelemetry区别?
Brave是一个分布式链路跟踪插桩库。通过拦截请求的方式收集时序数据并通过链路标识来关联传播。
通常会将链路跟踪数据发送到Zipkin,也可以使用第三方插件方式发送到其他替代服务。
Brave提供的API,配置选项较少,但其集成比较简单,适合不需要复杂自定义的场景。
Brave主要是围绕Zipkin的生态发展,尽管稳定且成熟,但还是有一定的局限性。
OpenTelemetry官方地址 (opens new window)
OpenTelemetry是未来的观测标准【本项目就是使用这个标准,来收集指标和链路】。 提供更广泛的API和配置选项,支持更多自定义的操作,适合需要高度可扩展性和灵活性的应用。
可以用它来检测,生成,收集和导出观测数据【指标、日志和跟踪(链路)】,可以用来分析软件的性能和行为。
更重要是该项目是一个活跃且快速发展的项目,并且得到更广泛的行业支持,具有更广泛的社区支持和更丰富的生态系统,蕴盖了多个云供应商和监控工具。
# elasticsearch
elasticsearch官方文档 (opens new window)
elasticsearch是一个分布式、RESTFul风格的搜索和数据分析引擎,同时是可扩展的数据存储和矢量数据库,能够应对日益增多的各种用例。
注意:什么是矢量?我个人的理解是对某种事物的特征描述,通过特征描述可以大致还原出整个事物
elasticsearch能够存储海量数据,实现闪电般的搜索速度,精细的相关性调整以及强大的分析能力,并且能够轻松进行规模扩展。
# beats
beats是一个免费且开发的平台,集成了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向Logstash
或Elasticsearch发送数据。
# filebeat
filebeat官方文档 (opens new window)
filebeat是使用go语言开发的,用于转发和汇总日志与文件,让简单的事情不再繁杂。
# logstash
logstash官方地址 (opens new window)
logstash是一个开源数据收集引擎,具有流水线功能,可以动态接收来自不同数据源的数据,并将数据按照一定的规则进行数据清洗,然后写入对应的目标数据源。
任何类型事件可以通过广泛的input、output、filter插件来进行清洗和转换,丰富的编解码器进一步简化开发。
# kibana
kibana是一个用户界面,可让您可视化Elasticsearch数据并管理ElasticStack。
- 搜索文档,分析文档和查找安全漏洞
- 数据可视化
- 管理,监控Elastic Stack集群,以及权限控制
# Elastic Stack
Elastic Stack的核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash
ELK = Elasticsearch + Logstash + Kibana
EFK = Elasticsearch + Filebeat + Logstash + Kibana
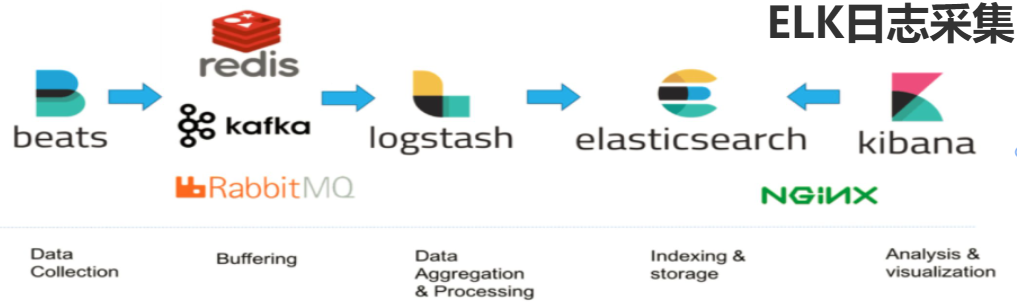
# 安装ELK
请参考es+kibana安装教程,请一定要使用这个链接 (opens new window)
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.15.0
container_name: elasticsearch
# 保持容器在没有守护程序的情况下运行
tty: true
restart: always
privileged: true
ports:
- "9200:9200"
- "9300:9300"
volumes:
- ./elasticsearch8/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- ./elasticsearch8/data:/usr/share/elasticsearch/data
- ./elasticsearch8/logs:/usr/share/elasticsearch/logs
- ./elasticsearch8/plugins:/usr/share/elasticsearch/plugins
- ./elasticsearch8/config/certs/elastic-certificates.p12:/usr/share/elasticsearch/config/certs/elastic-certificates.p12
environment:
- TZ=Asia/Shanghai
- ES_JAVA_OPTS=-Xmx1g -Xms1g
- ELASTIC_PASSWORD=laokou123
networks:
- iot_network
ulimits:
memlock:
soft: -1
hard: -1
kibana:
image: kibana:8.15.0
container_name: kibana
# 保持容器在没有守护程序的情况下运行
tty: true
restart: always
privileged: true
environment:
- TZ=Asia/Shanghai
ports:
- "5601:5601"
volumes:
- ./kibana8/config/kibana.yml:/usr/share/kibana/config/kibana.yml
networks:
- iot_network
depends_on:
- elasticsearch
deploy:
resources:
limits:
cpus: '0.50'
memory: 1G
networks:
iot_network:
driver: bridge
kibana.yaml配置
server.name: kibana
server.host: 0.0.0.0
server.port: 5601
server.ssl.enabled: false
elasticsearch.hosts: [ "https://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
elasticsearch.ssl.verificationMode: none
elasticsearch.username: "kibana_system"
elasticsearch.password: "laokou123"
i18n.locale: zh-CN
docker-compose up -d
# 从docker进入Linux系统
docker exec -it elasticsearch /bin/bash
cd /usr/share/elasticsearch
# 设置kibana密码
./bin/elasticsearch-setup-passwords interactive
# 移除容器,重新启动
docker-compose stop elasticsearch kibaba
docker-compose rm
# 重启
docker-compose restart elasticsearch kibaba
# 使用
# log4j2使用
引入依赖
<dependencys>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- log4j2的AsyncLogger时需要包含disruptor -->
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
</dependencys>
开启异步日志,请创建log4j2.component.properties
log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
注意:请切换至prod环境
log4j2配置
以auth服务为例
<Configuration status="INFO" monitorInterval="5">
<!-- 变量配置 -->
<Properties>
<!-- 存放目录 -->
<property name="LOG_PATH" value="/opt/auth"/>
<!-- 日志文件大小 -->
<property name="LOG_ROLL_SIZE" value="1 GB"/>
<!-- 服务名称 -->
<property name="SERVICE_ID" value="laokou-auth"/>
<!-- -Dlog4j.skipJansi=false -->
<!-- 日志格式 -->
<!--
%d 日期
%t 线程
对于系统参数,使用${sys:xxx}即可,例如读取-Dserver.port=1111,即${sys:server.port}
spanId => %X{spanId}
traceId => %X{traceId}
-->
<property name="LOG_CONSOLE_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} ---> [${SERVICE_ID} - ${sys:address:-}] - [%X{traceId}] - [%X{spanId}] - [ %style{%-5level}{red}] - [%t] - %logger : %msg%n"/>
<property name="LOG_FILE_PATTERN"
value="%d{yyyy-MM-dd HH:mm:ss.SSS} ---> [${SERVICE_ID} - ${sys:address:-}] - [%X{traceId}] - [%X{spanId}] - [ %-5level] - [%t] - %logger : %msg%n"/>
<!-- 日志保留30天 -->
<property name="LOG_DAYS" value="30"/>
<!-- 1天滚动一次 -->
<property name="LOG_INTERVAL" value="1"/>
</Properties>
<Appenders>
<!-- 控制台输出 -->
<Console name="console" target="SYSTEM_OUT">
<PatternLayout pattern="${LOG_CONSOLE_PATTERN}"/>
</Console>
<RollingRandomAccessFile name="file" fileName="${LOG_PATH}/${SERVICE_ID}.log"
filePattern="${LOG_PATH}/%d{yyyyMMdd}/${SERVICE_ID}_%d{yyyy-MM-dd}.%i.log.gz"
immediateFlush="false">
<Filters>
<ThresholdFilter level="ERROR" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
<PatternLayout pattern="${LOG_FILE_PATTERN}"/>
<Policies>
<TimeBasedTriggeringPolicy interval="${LOG_INTERVAL}"/>
<SizeBasedTriggeringPolicy size="${LOG_ROLL_SIZE}"/>
</Policies>
<DefaultRolloverStrategy max="${LOG_DAYS}"/>
</RollingRandomAccessFile>
<RollingRandomAccessFile name="failover_kafka" fileName="${LOG_PATH}/${SERVICE_ID}_kafka.log"
filePattern="${LOG_PATH}/%d{yyyyMMdd}/${SERVICE_ID}_kafka_%d{yyyy-MM-dd}.%i.log.gz"
immediateFlush="false">
<Filters>
<ThresholdFilter level="INFO" onMatch="ACCEPT" onMismatch="DENY"/>
</Filters>
<PatternLayout pattern="${LOG_FILE_PATTERN}"/>
<Policies>
<TimeBasedTriggeringPolicy interval="${LOG_INTERVAL}"/>
<SizeBasedTriggeringPolicy size="${LOG_ROLL_SIZE}"/>
</Policies>
<DefaultRolloverStrategy max="${LOG_DAYS}"/>
</RollingRandomAccessFile>
<Failover name="failover" primary="kafka" retryIntervalSeconds="600">
<Failovers>
<AppenderRef ref="failover_kafka"/>
</Failovers>
</Failover>
<Async name="async_file" bufferSize="2000" blocking="false">
<AppenderRef ref="file"/>
</Async>
<Async name="async_kafka" bufferSize="2000" blocking="false">
<AppenderRef ref="failover"/>
</Async>
<Kafka name="kafka" topic="trace-log" ignoreExceptions="false">
<PatternLayout>
<!--
注意:真实的生产环境,日志打印的内容是五花八门,日志内容会出现一些莫名其他的特殊符号,导致json无法反序列化
因此,可以利用Pattern Layout 提供的标签enc,enc支持4种转义,HTML/XML/JSON/CRLF,默认进行HTML转义
目前,只对JSON处理,即%enc{%m}{JSON} => {"msg":"%enc{%m}{JSON}"}
-->
<pattern>
{
"serviceId":"${SERVICE_ID}",
"profile":"prod",
"dateTime":"%d{yyyy-MM-dd HH:mm:ss.SSS}",
"traceId":"%X{traceId}",
"spanId":"%X{spanId}",
"address":"${sys:address:-}",
"level":"%-5level",
"thread":"%thread",
"logger":"%logger",
"msg":"%enc{%m}{JSON}"
}
</pattern>
</PatternLayout>
<!-- 生产者发送消息最大阻塞时间,单位为毫秒,生产者阻塞超过2秒,则抛出异常并中断发送【生产者内部缓冲区已满或元数据不可用,send()会阻塞等待】 -->
<Property name="max.block.ms">2000</Property>
<!-- 客户端发送请求到kafka broker超时时间,单位为毫秒,2秒内没有从kafka broker收到响应,则认为请求失败则抛出异常 -->
<Property name="request.timeout.ms">2000</Property>
<Property name="bootstrap.servers">kafka:9092</Property>
<Property name="value.serializer">org.apache.kafka.common.serialization.ByteArraySerializer</Property>
</Kafka>
</Appenders>
<!--
additivity => 需不需要打印此logger继承的父logger,false只打印当前logger,true继续打印上一层logger,直至root
includeLocation => 显示文件行数,方法名等信息,true显示,false不显示,可以减少日志输出的体积,加快日志写入速度
-->
<Loggers>
<AsyncLogger name="org.laokou" additivity="FALSE" includeLocation="FALSE" level="INFO">
<AppenderRef ref="async_kafka"/>
</AsyncLogger>
<AsyncRoot level="ERROR" additivity="FALSE" includeLocation="FALSE">
<AppenderRef ref="console"/>
<AppenderRef ref="async_file"/>
</AsyncRoot>
</Loggers>
</Configuration>
# micrometer使用
依赖
<dependencys>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-otel</artifactId>
</dependency>
<!-- openfeign集成micrometer -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-micrometer</artifactId>
</dependency>
</dependencys>
@Component
@RequiredArgsConstructor
public class TraceUtil {
private final Tracer tracer;
public String getTraceId() {
TraceContext context = getContext();
return ObjectUtil.isNull(context) ? "" : context.traceId();
}
public String getSpanId() {
TraceContext context = getContext();
return ObjectUtil.isNull(context) ? "" : context.spanId();
}
private TraceContext getContext() {
return tracer.currentTraceContext().context();
}
}
# elasticsearch使用
引入依赖
<dependencies>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
</dependencies>
异步创建索引和批量同步索引【详情请查看本项目源码,laokou-common-elasticsearch】
@Slf4j
@Component
@RequiredArgsConstructor
public class ElasticsearchTemplate {
private final ElasticsearchAsyncClient elasticsearchAsyncClient;
public <TDocument> CompletableFuture<Boolean> asyncCreateIndex(String name, String alias, Class<TDocument> clazz) {
return asyncExist(List.of(name)).thenApplyAsync(resp -> {
if (resp) {
log.info("索引:{} -> 创建索引失败,索引已存在", name);
return Boolean.FALSE;
}
return Boolean.TRUE;
}).thenApplyAsync(resp -> {
if (resp) {
Document document = convert(name, alias, clazz);
elasticsearchAsyncClient.indices().create(getCreateIndexRequest(document)).thenApplyAsync(response -> {
if (response.acknowledged()) {
log.info("索引:{} -> 创建索引成功", name);
return Boolean.TRUE;
} else {
log.info("索引:{} -> 创建索引失败", name);
return Boolean.FALSE;
}
});
}
return Boolean.FALSE;
});
}
public CompletableFuture<Boolean> asyncBulkCreateDocument(String index, Map<String, Object> map) {
return elasticsearchAsyncClient
.bulk(bulk -> bulk.index(index).refresh(Refresh.True).operations(getBulkOperations(map)))
.thenApplyAsync(resp -> {
if (resp.errors()) {
log.info("索引:{} -> 异步批量同步索引失败", index);
return Boolean.FALSE;
} else {
log.info("索引:{} -> 异步批量同步索引成功", index);
return Boolean.TRUE;
}
});
}
}
# logstash使用
注意:logstash是用的本项目自己搞的轻量级日志收集引擎
核心源码
@Slf4j
@Component
@RequiredArgsConstructor
public class TraceHandler {
private static final String TRACE = "trace_log";
private final ElasticsearchTemplate elasticsearchTemplate;
@KafkaListener(topics = "trace_log", groupId = "trace_consumer_group")
public void kafkaConsumer(List<String> messages, Acknowledgment ack) {
try {
Map<String, Object> dataMap = messages.stream()
.map(this::getTraceIndex)
.filter(Objects::nonNull)
.toList()
.stream()
.collect(Collectors.toMap(TraceIndex::getId, traceIndex -> traceIndex));
if (MapUtil.isNotEmpty(dataMap)) {
elasticsearchTemplate.asyncCreateIndex(getIndexName(), TRACE, TraceIndex.class)
.thenAcceptAsync(res -> elasticsearchTemplate.asyncBulkCreateDocument(getIndexName(), dataMap));
}
} catch (Throwable e) {
log.error("分布式链路写入失败,错误信息:{}", e.getMessage());
} finally {
ack.acknowledge();
}
}
private TraceIndex getTraceIndex(String str) {
try {
TraceIndex traceIndex = JacksonUtil.toBean(str, TraceIndex.class);
String traceId = traceIndex.getTraceId();
String spanId = traceIndex.getSpanId();
if (isTrace(traceId, spanId)) {
traceIndex.setId(String.valueOf(IdGenerator.defaultSnowflakeId()));
return traceIndex;
}
} catch (Exception ex) {
log.error("分布式链路日志JSON转换失败,错误信息:{}", ex.getMessage());
}
return null;
}
private boolean isTrace(String traceId, String spanId) {
return isTrace(traceId) && isTrace(spanId);
}
private boolean isTrace(String str) {
return StringUtil.isNotEmpty(str) && !str.startsWith("${") && !str.endsWith("}");
}
private String getIndexName() {
return TRACE + "_" + DateUtil.format(DateUtil.nowDate(), "yyyyMMdd");
}
@Data
@Index(setting = @Setting(refreshInterval = "-1"))
public static final class TraceIndex implements Serializable {
@Field(type = Type.LONG)
private String id;
@Field(type = Type.KEYWORD)
private String serviceId;
@Field(type = Type.KEYWORD)
private String profile;
@Field(type = Type.DATE, format = "yyyy-MM-dd HH:mm:ss.SSS")
private String dateTime;
@Field(type = Type.KEYWORD, index = true)
private String traceId;
@Field(type = Type.KEYWORD, index = true)
private String spanId;
@Field(type = Type.KEYWORD)
private String address;
@Field(type = Type.KEYWORD)
private String level;
@Field(type = Type.KEYWORD)
private String thread;
@Field(type = Type.KEYWORD)
private String logger;
@Field(type = Type.KEYWORD)
private String msg;
}
}
# kibana使用
1.启动nacos/auth/gateway/logstash
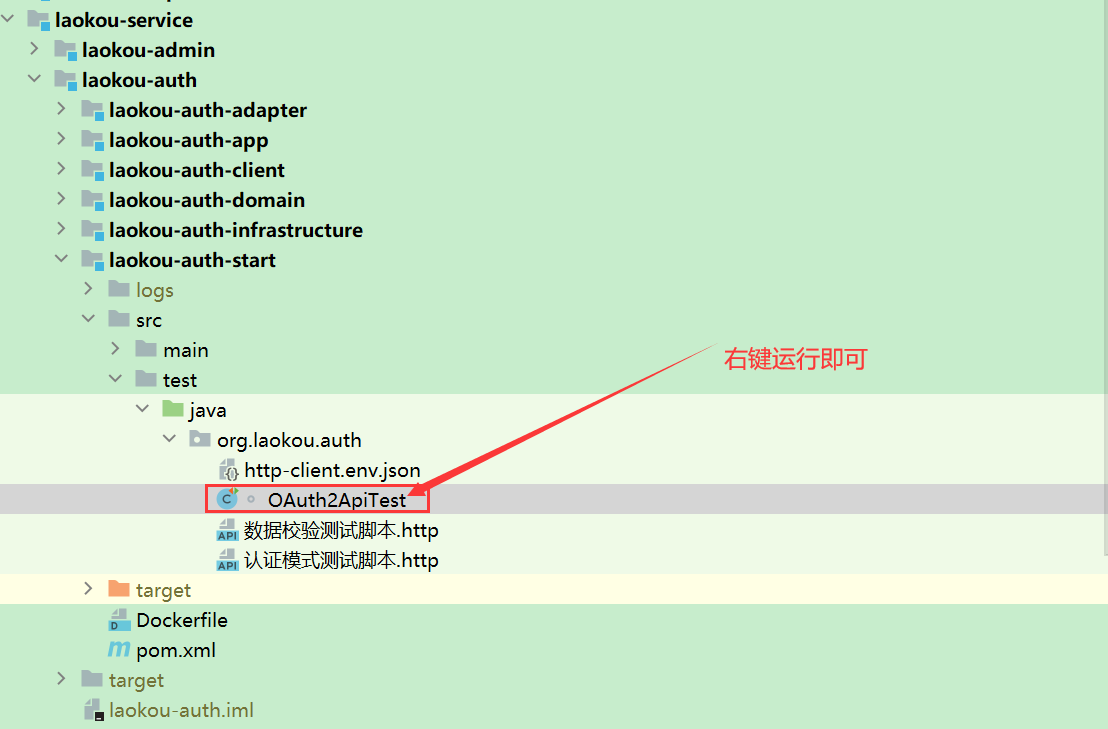
2.运行auth测试用例
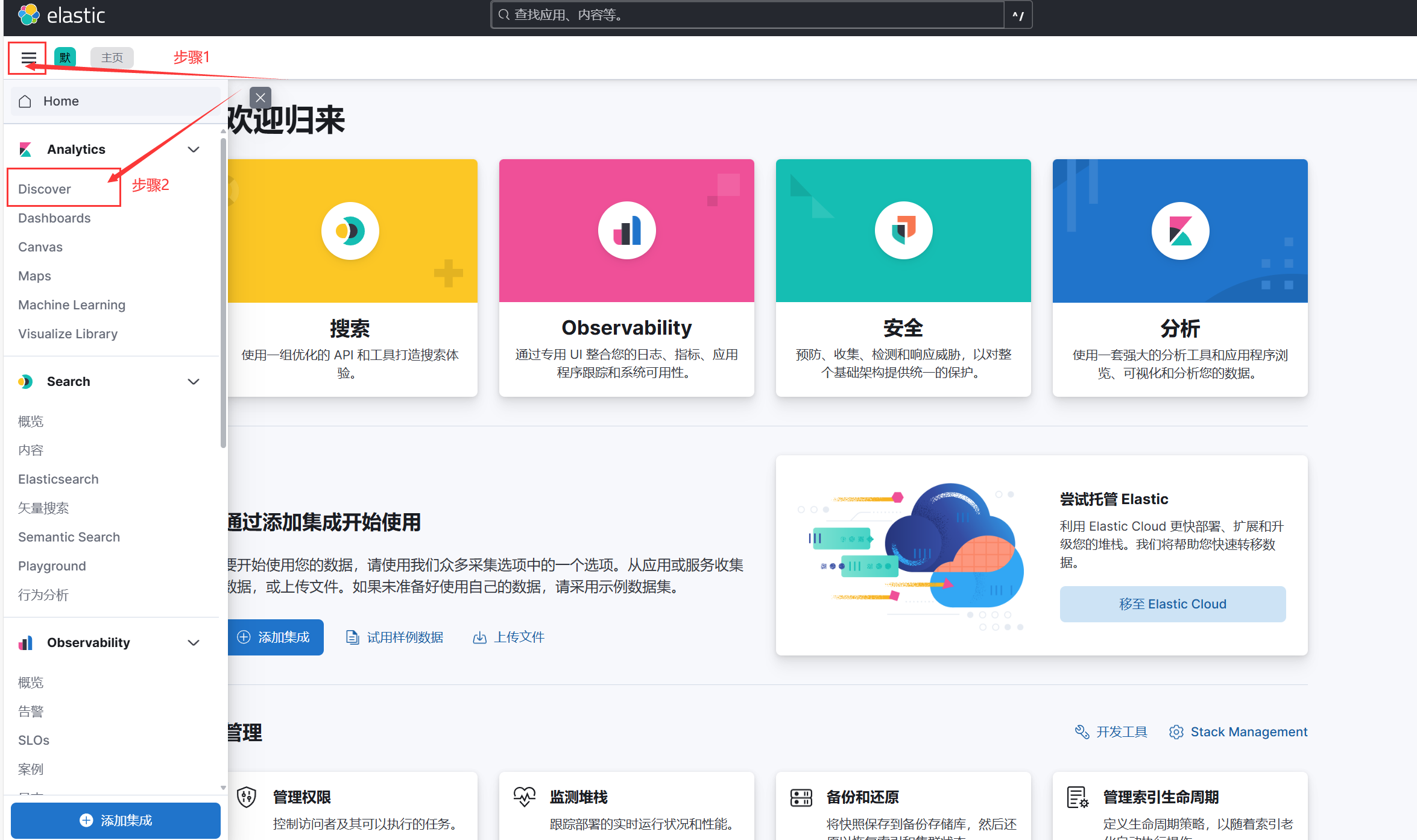
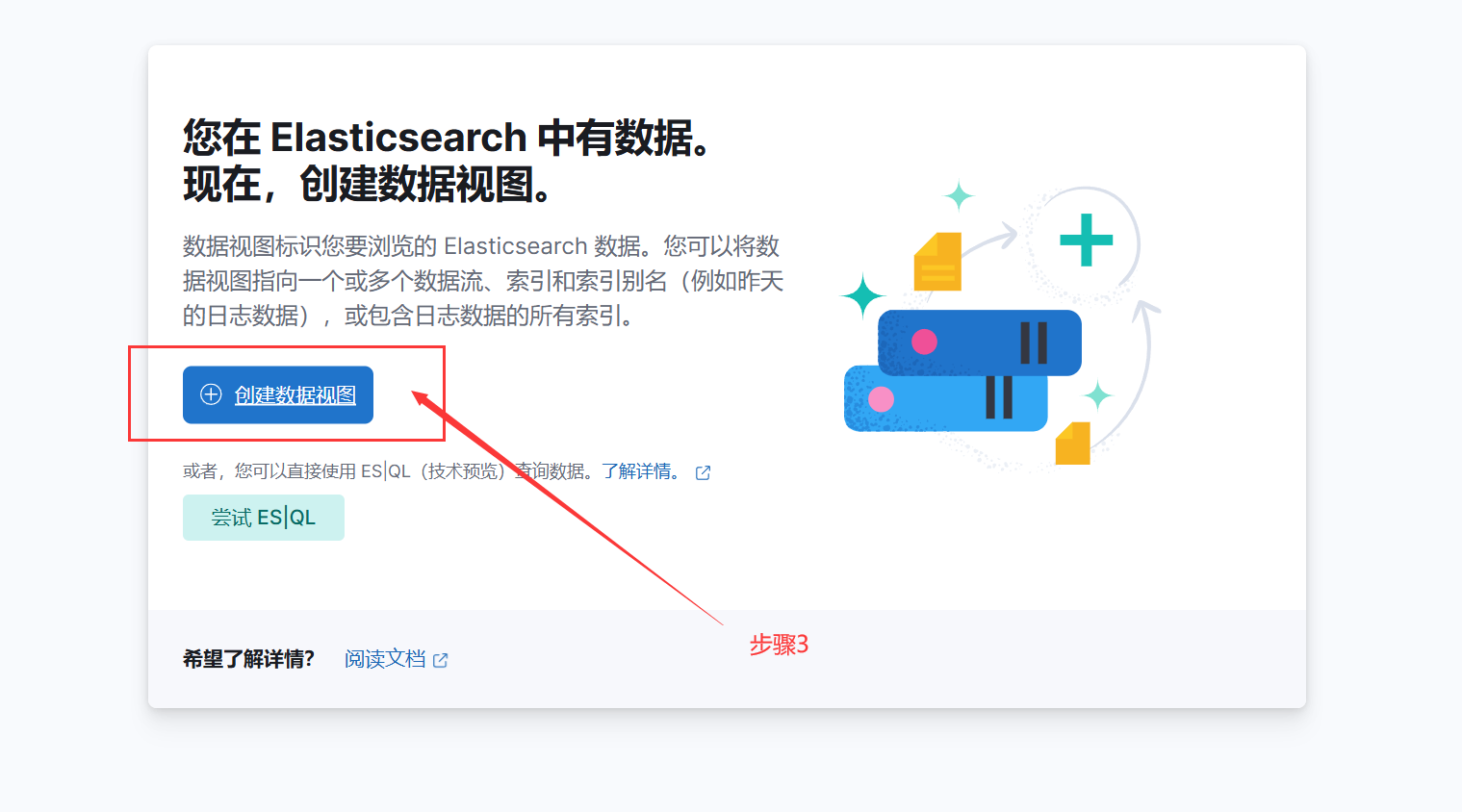
3.打开kibana控制台
输入设置好的账号密码 => elastic/laokou123
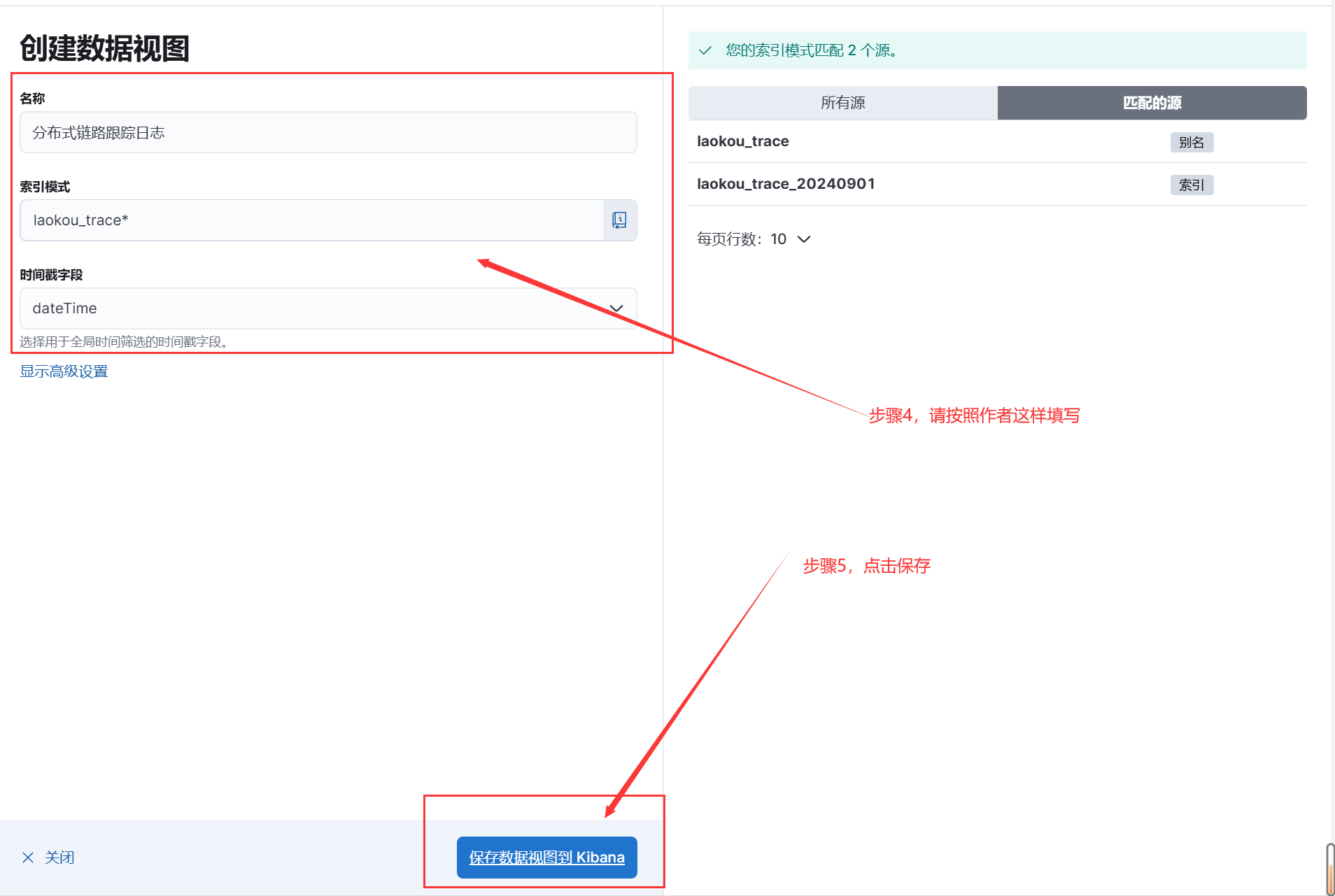
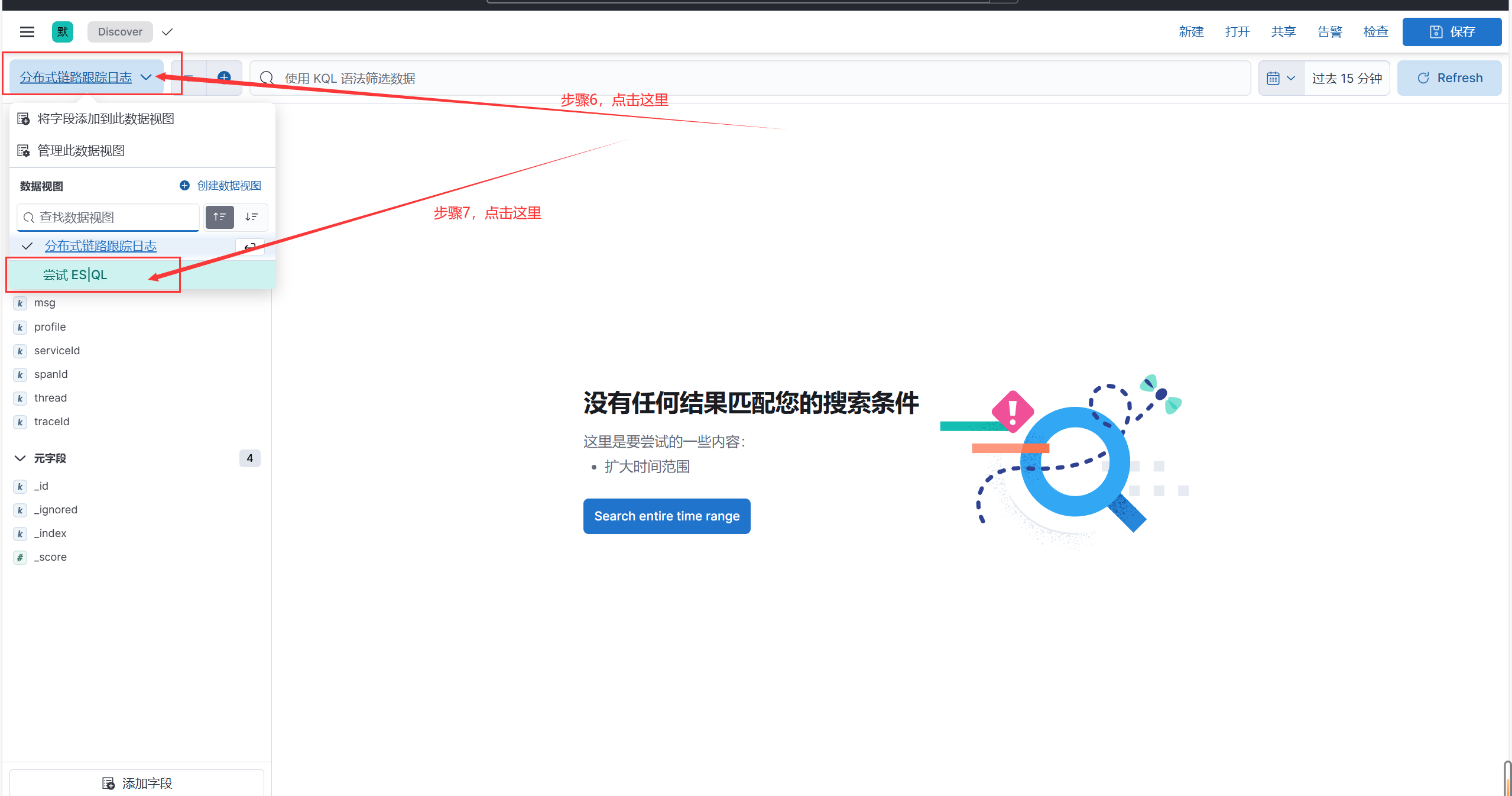
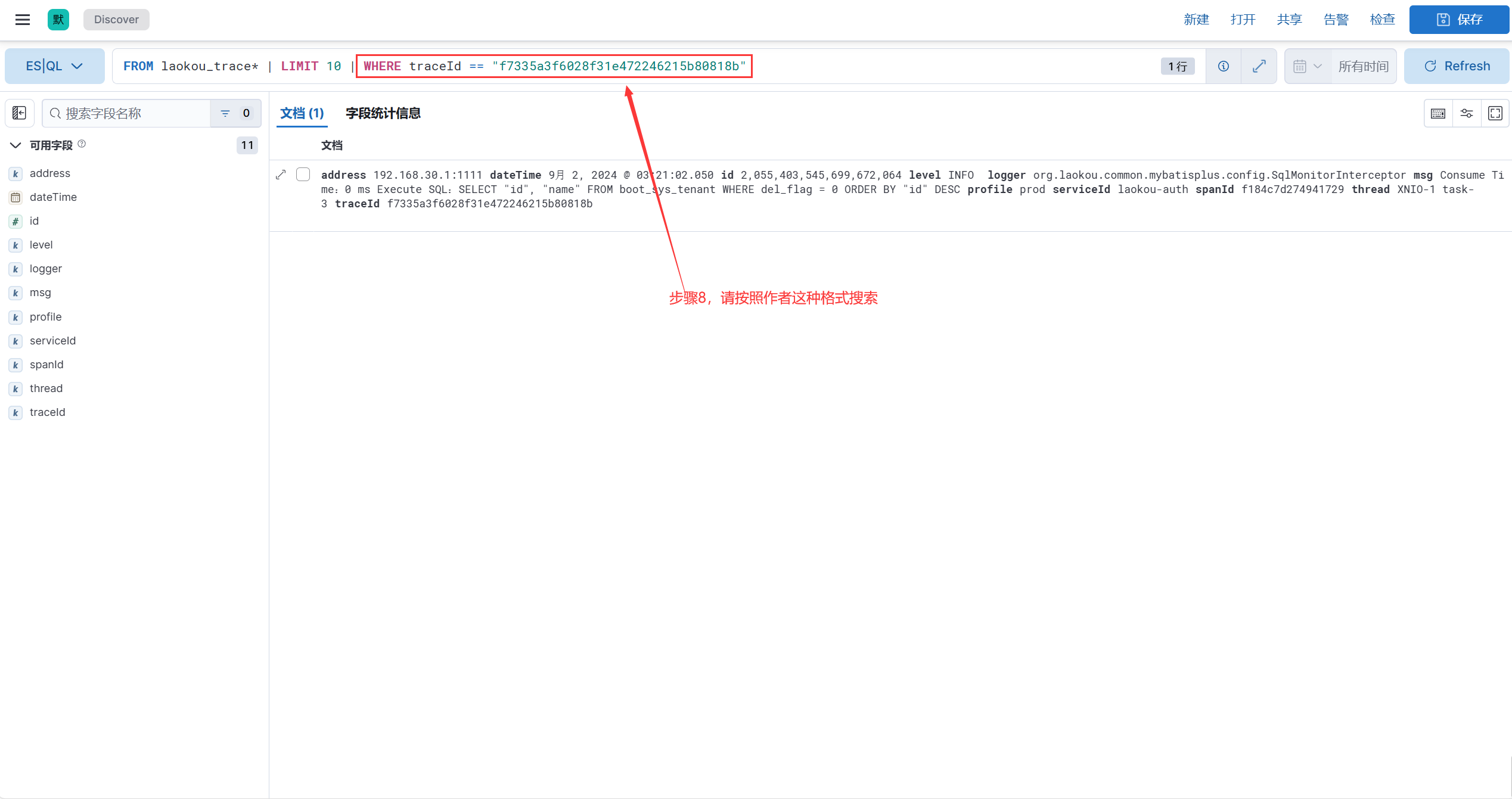
补充
本项目使用分布链路跟踪,只需要引入依赖
<dependency>
<groupId>org.laokou</groupId>
<artifactId>laokou-common-trace</artifactId>
</dependency>
至此,大功告成,恭喜你看完分布式链路跟踪之ELK日志,你学废了码?
我是老寇,我们下次再见啦!